《机器之心》简介
机器之心
出典:知道
最爱的人
调整kernel size的时间是多久?虽然经常被无视,但是简单地放大的话会很吃惊。
卷网(CNN)的深度、宽度、groups、输入分辨率的升级参数交错时,会无意中想起设计下一个kernel size吗?一直这样清楚,但总是被忽略,一直默认为3x3或5x5吗?
在Transformer愉快调整时,希望型号简单高效,配置简单,下游任务性能不弱于Transformer?带来朴素的快乐吗?
最近,清华大学、望远科学技术等研究人员在CVPR 2022上发表的工作表明,CNN的kernel size非常重要,但它是经常被忽视的设计次元。在现代模型设计的支持下,卷芯越大越暴力,上升点也越有效,直到31x31非常work(如下表5所示,左侧栏表示模型的四个阶段的每一个kernel size)!
在一个概述的下游任务中,我们提出的超大卷核模型RepLKNet比Transformer(如Swin)的性能更好或同等。
 论文地址:https://arxiv.org/abs/2203.06717MegEngine代码和型号:https://github.com/megvii-research/RepLKNetPyTorch代码和型号:https://github.com/DingXiaoH/RepLKNet-pytorch
论文地址:https://arxiv.org/abs/2203.06717MegEngine代码和型号:https://github.com/megvii-research/RepLKNetPyTorch代码和型号:https://github.com/DingXiaoH/RepLKNet-pytorch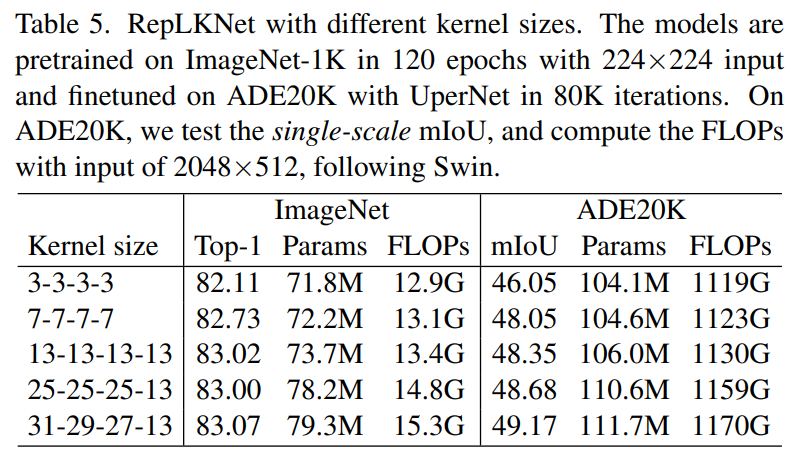 太长了不看版
以下是2分钟内可以看到的内容的总结。
A.CNN和Transformer相关行业的知识和理解有什么贡献。
我们挑战了以下习惯认识。
1.超大容量不但不上升,而且有点下降?我们证明了过去没有人使用过超大容量,现在也不是不能使用。人类对科学的认识总是螺旋状上升,在现代CNN设计(shortcut、重参数化等)的支持下,kernel size上升得越大。
2.超大容量效率差的腐蚀63?我们发现超大depth-wise音量不会增加FLOPs。再加上下层优化,速度变快,31x31的计算密度达到最高3x3的70倍。
3.大容量只能用于大的feature map吗?发现在7x7的feature map中可以用13x13卷起。
4.ImageNet点数说明全部吗?我们发现下游任务的性能可能与ImageNet无关。
5.超深CNN(ResNet-152等)堆积了大量3x3,感觉野地很大吗?我们发现,深层小kerner模型能有效感知原野其实很小。相反,少量的超大卷核的有效感受范围非常大。
6.Transformers(ViT、Swin等)在下游任务中性能强是因为self-attention(Query-Key-Value的设计形式)本质上强?通过超大卷积核的验证,发现kernel size可能是下游上升点的关键。
B.我们做了什么具体的工作。
1.通过一系列探索性实验,总结了现代CNN中应用超大核的五个准则。
在depth-wise超大容量中,再加上较低优化(集成到开放源框架中的MegEngine)和shortcut,以小音量核心进行重参数化(即,参照结构重参数化方法论、去年的RepVGG、参考文献[1]),看下游任务的性能不仅是ImageNet分数的高低小feature map,即使是大容量,也可以以通常的分辨率训练大kerner模型2。基于以上指导方针,我们提出了一种简单参考Swin Transformer的宏架构,大量使用27x27、31x31等超大容量的架构RepLKNet。这个架构的其他部分非常简单,是1×1卷、Batch正规等令人满意的简单结构,完全不使用attention。
3.基于超大卷芯,有效的感受野、shape bias(决定模型时是看物体的形状还是局部的纹理)、Transformers性能强的理由等话题的讨论和分析。ResNet-152等传统的深层小kernel模型的有效感受野实际上不大,大kerel模型不仅有效感受野更大,而且与人(shape bias高)相似。Transformer可能不是self-attention的具体形式,而是大kernel。
例如,图1示出了ResNet-101、ResNet-152、全13×13的RepLKNet、Kernel分别大到31x31的RepLKNet的有效感受野,并且浅的大的kernel模型的有效感受野非常大。
太长了不看版
以下是2分钟内可以看到的内容的总结。
A.CNN和Transformer相关行业的知识和理解有什么贡献。
我们挑战了以下习惯认识。
1.超大容量不但不上升,而且有点下降?我们证明了过去没有人使用过超大容量,现在也不是不能使用。人类对科学的认识总是螺旋状上升,在现代CNN设计(shortcut、重参数化等)的支持下,kernel size上升得越大。
2.超大容量效率差的腐蚀63?我们发现超大depth-wise音量不会增加FLOPs。再加上下层优化,速度变快,31x31的计算密度达到最高3x3的70倍。
3.大容量只能用于大的feature map吗?发现在7x7的feature map中可以用13x13卷起。
4.ImageNet点数说明全部吗?我们发现下游任务的性能可能与ImageNet无关。
5.超深CNN(ResNet-152等)堆积了大量3x3,感觉野地很大吗?我们发现,深层小kerner模型能有效感知原野其实很小。相反,少量的超大卷核的有效感受范围非常大。
6.Transformers(ViT、Swin等)在下游任务中性能强是因为self-attention(Query-Key-Value的设计形式)本质上强?通过超大卷积核的验证,发现kernel size可能是下游上升点的关键。
B.我们做了什么具体的工作。
1.通过一系列探索性实验,总结了现代CNN中应用超大核的五个准则。
在depth-wise超大容量中,再加上较低优化(集成到开放源框架中的MegEngine)和shortcut,以小音量核心进行重参数化(即,参照结构重参数化方法论、去年的RepVGG、参考文献[1]),看下游任务的性能不仅是ImageNet分数的高低小feature map,即使是大容量,也可以以通常的分辨率训练大kerner模型2。基于以上指导方针,我们提出了一种简单参考Swin Transformer的宏架构,大量使用27x27、31x31等超大容量的架构RepLKNet。这个架构的其他部分非常简单,是1×1卷、Batch正规等令人满意的简单结构,完全不使用attention。
3.基于超大卷芯,有效的感受野、shape bias(决定模型时是看物体的形状还是局部的纹理)、Transformers性能强的理由等话题的讨论和分析。ResNet-152等传统的深层小kernel模型的有效感受野实际上不大,大kerel模型不仅有效感受野更大,而且与人(shape bias高)相似。Transformer可能不是self-attention的具体形式,而是大kernel。
例如,图1示出了ResNet-101、ResNet-152、全13×13的RepLKNet、Kernel分别大到31x31的RepLKNet的有效感受野,并且浅的大的kernel模型的有效感受野非常大。
 有效地感到原野。
C.建议体系结构RepLKNet的效果如何?
1.ImageNet相当于Swin-Base。在追加的数据训练下,超大型模型达到了最高87.8%的正解率。超大卷芯原本不是为了刷ImageNet而设计的,这个分数也能令人满意。
2.在Cityyscapes的意义划分中,仅ImageNet-1K pretain的RepLKNet-Base可以超过ImageNet-22K pretain的Swin-Large。这超出了模型级别和数据级别。
3.在ADE20K的意义划分中,ImageNet-1K pretrain的模型大大超过了传统的诸如ResNet、ResNeSt等小kerner的CNN。基本水平模型显著超过Swin,Large模型相当于Swin。超大型规模模型达到了56%的mIoU。
4.在COCO目标检测中,大幅超过同量级别的以往机型ResNeXt-101(超过4.4的mAP)相当于Swin,是超大量级别达到55.5%的mAP。
以下详细介绍。
初心:我们为什么需要超大的kernel size?
现在这个时代,为什么要研究听起来怀旧的大kerner呢。
1.复兴“误杀”的设计要素,并取其正名。历史上,AlexNet使用过11×11卷,但在VGG登场后,大的kernel逐渐被淘汰,展示了从浅的kernel到深的kernel的小模型设计模型的转换。这个转换的原因有,大的kernel的效率差(音量的参数量和计算量与kernel size的平方成比例),增大kernel size的话,精度反而变差等。可是时代变了,历史上不工作的大的kerner,在现代技术的加持下能工作吗。
2.克服传统的深层小kerner CNN的固有缺陷。相信大的kerner可以用几个小的kernel来代替。例如,一个7x7可以被三个3x3替换,这样速度很快(3x3<1 x 7 x 7)、効果がより良い(より深く、非線形性がより多い)。深層小kernelの積み重ねは最適化の問題を生みやすいが、この問題はすでにResNetによって解決されている(ResNet-152は50層3 x 3のボリュームがある)と考える学生もいるが、このやり方にはどんな欠陥があるのだろうか。--ResNetがこの問題を解決する代償として,モデルは理論上の最大感受野が大きくても実質的な有効深さはそれほど深くない(文献2参照),したがって有効感受野は大きくない.これは、従来のCNNがImageNetでTransformerとあまり差がないが、下流のタスクでTransformerに及ばない理由かもしれない。つまり、ResNetは実質的に「深層モデルの最適化が難しい」という問題を回避するのに役立ち、実際には解決されていない。深くてkernelの小さいモデルにこのような本質的な問題がある以上、浅くてkernelの大きい設計モデルの効果はどうなるのだろうか。
3.Transformerがworkした理由を理解する。Transformerパフォーマンスは、特に検出、分割などの下流タスクで群を抜くことが知られています。Transformerの基本コンポーネントはself-attentionであり、self-attentionの本質はグローバルスケールまたは大きなウィンドウ内でQuery-Key-Value演算を行うことである。ではTransformerの性能が強い理由は何なのか、Query-Key-Valueのデザイン形式なのか。「グローバルスケールや大きなウィンドウ」が鍵になるのではないかと推測しています。CNNに対応するには、超大ボリューム核で検証する必要がある。
探索実験.
大きなkernelがどのように使うべきかを理解するために,MobileNet V 2上で一連の探索実験を行い,5つの準則をまとめた。ここでは詳細を省略して結論だけを言います。
1.depth-wise大kernelで、かなり効率的にできます。我々の最適化(オープンソースフレームワークMegEngineに統合された)の下で、31 x 31 depth-wiseボリュームの使用時間は最低3 x 3ボリュームの1.5倍に達し、前者のFLOPsは後者の106倍(31 x 31/9)であり、これは前者の効率が後者の71倍であることを意味する。
2.identity shortcutを持たずにkernelを大きくすると大幅に落ちる(ImageNetが15%落ちた);shortcutを持って、kernelを大きくしてから上昇します。
3.kernel sizeをさらに大きくするには、大きなkernelから超大きなkernelまで、小さなkernelで構造再パラメータ化することができる(文献1参照)。すなわち,訓練時に並行して3 x 3または5 x 5のボリュームを加え,訓練完了後に小さなkernelを等価に大きなkernelに統合する.これにより,モデルは異なるスケールの特徴を効果的に捉えることができる.しかし,データセットが小さいほど,モデルが小さいほど,再パラメータ化が重要であることが分かった。逆に,我々の超大規模データセットMegData 73 Mでは,重パラメータ化の向上は小さい(0.1%).この発見はViTと似ている:データ規模が大きいほどinductive biasは重要ではない。
4.私たちが望んでいるのは、ImageNetの上昇点ではなく、ターゲットタスクの上昇点であり、ImageNetの精度は下流タスクと必ずしも関連していない。kernel sizeがますます大きくなるにつれて、ImageNetでは上昇点はなくなりましたが、Cityscapes、ADE 20 Kの意味分割では1~2点上昇することができますが、kernelを大きくすることによる追加のパラメータ量と計算量は少なく、性価比は極めて高いです!
5.ちょっと反直感的なのは、7 x 7の小さなfeature mapで13 x 13でも上がる!つまり、大きなkernelモデルは必ずしも大きな解像度で訓練する必要はありません。小さなkernelモデルと差の少ない訓練方法でいいです。速くて節約できます。
RepLKNet:超大ボリュームコアアーキテクチャ
私たちはSwinを主な対比対象とし,SOTAをブラシするつもりはないので,Swinのマクロアーキテクチャを簡単に参考にして超大ボリュームコアアーキテクチャを設計した。このアーキテクチャは主にattentionを超大ボリュームとそれに組み合わせた構造に変え、CNNスタイルの変更を加えることにある。以上の5つのガイドラインによれば、RepLKNetの設計要素にはshortcut、depth-wise超大型kernel、小kernel再パラメータ化などが含まれる。
有效地感到原野。
C.建议体系结构RepLKNet的效果如何?
1.ImageNet相当于Swin-Base。在追加的数据训练下,超大型模型达到了最高87.8%的正解率。超大卷芯原本不是为了刷ImageNet而设计的,这个分数也能令人满意。
2.在Cityyscapes的意义划分中,仅ImageNet-1K pretain的RepLKNet-Base可以超过ImageNet-22K pretain的Swin-Large。这超出了模型级别和数据级别。
3.在ADE20K的意义划分中,ImageNet-1K pretrain的模型大大超过了传统的诸如ResNet、ResNeSt等小kerner的CNN。基本水平模型显著超过Swin,Large模型相当于Swin。超大型规模模型达到了56%的mIoU。
4.在COCO目标检测中,大幅超过同量级别的以往机型ResNeXt-101(超过4.4的mAP)相当于Swin,是超大量级别达到55.5%的mAP。
以下详细介绍。
初心:我们为什么需要超大的kernel size?
现在这个时代,为什么要研究听起来怀旧的大kerner呢。
1.复兴“误杀”的设计要素,并取其正名。历史上,AlexNet使用过11×11卷,但在VGG登场后,大的kernel逐渐被淘汰,展示了从浅的kernel到深的kernel的小模型设计模型的转换。这个转换的原因有,大的kernel的效率差(音量的参数量和计算量与kernel size的平方成比例),增大kernel size的话,精度反而变差等。可是时代变了,历史上不工作的大的kerner,在现代技术的加持下能工作吗。
2.克服传统的深层小kerner CNN的固有缺陷。相信大的kerner可以用几个小的kernel来代替。例如,一个7x7可以被三个3x3替换,这样速度很快(3x3<1 x 7 x 7)、効果がより良い(より深く、非線形性がより多い)。深層小kernelの積み重ねは最適化の問題を生みやすいが、この問題はすでにResNetによって解決されている(ResNet-152は50層3 x 3のボリュームがある)と考える学生もいるが、このやり方にはどんな欠陥があるのだろうか。--ResNetがこの問題を解決する代償として,モデルは理論上の最大感受野が大きくても実質的な有効深さはそれほど深くない(文献2参照),したがって有効感受野は大きくない.これは、従来のCNNがImageNetでTransformerとあまり差がないが、下流のタスクでTransformerに及ばない理由かもしれない。つまり、ResNetは実質的に「深層モデルの最適化が難しい」という問題を回避するのに役立ち、実際には解決されていない。深くてkernelの小さいモデルにこのような本質的な問題がある以上、浅くてkernelの大きい設計モデルの効果はどうなるのだろうか。
3.Transformerがworkした理由を理解する。Transformerパフォーマンスは、特に検出、分割などの下流タスクで群を抜くことが知られています。Transformerの基本コンポーネントはself-attentionであり、self-attentionの本質はグローバルスケールまたは大きなウィンドウ内でQuery-Key-Value演算を行うことである。ではTransformerの性能が強い理由は何なのか、Query-Key-Valueのデザイン形式なのか。「グローバルスケールや大きなウィンドウ」が鍵になるのではないかと推測しています。CNNに対応するには、超大ボリューム核で検証する必要がある。
探索実験.
大きなkernelがどのように使うべきかを理解するために,MobileNet V 2上で一連の探索実験を行い,5つの準則をまとめた。ここでは詳細を省略して結論だけを言います。
1.depth-wise大kernelで、かなり効率的にできます。我々の最適化(オープンソースフレームワークMegEngineに統合された)の下で、31 x 31 depth-wiseボリュームの使用時間は最低3 x 3ボリュームの1.5倍に達し、前者のFLOPsは後者の106倍(31 x 31/9)であり、これは前者の効率が後者の71倍であることを意味する。
2.identity shortcutを持たずにkernelを大きくすると大幅に落ちる(ImageNetが15%落ちた);shortcutを持って、kernelを大きくしてから上昇します。
3.kernel sizeをさらに大きくするには、大きなkernelから超大きなkernelまで、小さなkernelで構造再パラメータ化することができる(文献1参照)。すなわち,訓練時に並行して3 x 3または5 x 5のボリュームを加え,訓練完了後に小さなkernelを等価に大きなkernelに統合する.これにより,モデルは異なるスケールの特徴を効果的に捉えることができる.しかし,データセットが小さいほど,モデルが小さいほど,再パラメータ化が重要であることが分かった。逆に,我々の超大規模データセットMegData 73 Mでは,重パラメータ化の向上は小さい(0.1%).この発見はViTと似ている:データ規模が大きいほどinductive biasは重要ではない。
4.私たちが望んでいるのは、ImageNetの上昇点ではなく、ターゲットタスクの上昇点であり、ImageNetの精度は下流タスクと必ずしも関連していない。kernel sizeがますます大きくなるにつれて、ImageNetでは上昇点はなくなりましたが、Cityscapes、ADE 20 Kの意味分割では1~2点上昇することができますが、kernelを大きくすることによる追加のパラメータ量と計算量は少なく、性価比は極めて高いです!
5.ちょっと反直感的なのは、7 x 7の小さなfeature mapで13 x 13でも上がる!つまり、大きなkernelモデルは必ずしも大きな解像度で訓練する必要はありません。小さなkernelモデルと差の少ない訓練方法でいいです。速くて節約できます。
RepLKNet:超大ボリュームコアアーキテクチャ
私たちはSwinを主な対比対象とし,SOTAをブラシするつもりはないので,Swinのマクロアーキテクチャを簡単に参考にして超大ボリュームコアアーキテクチャを設計した。このアーキテクチャは主にattentionを超大ボリュームとそれに組み合わせた構造に変え、CNNスタイルの変更を加えることにある。以上の5つのガイドラインによれば、RepLKNetの設計要素にはshortcut、depth-wise超大型kernel、小kernel再パラメータ化などが含まれる。
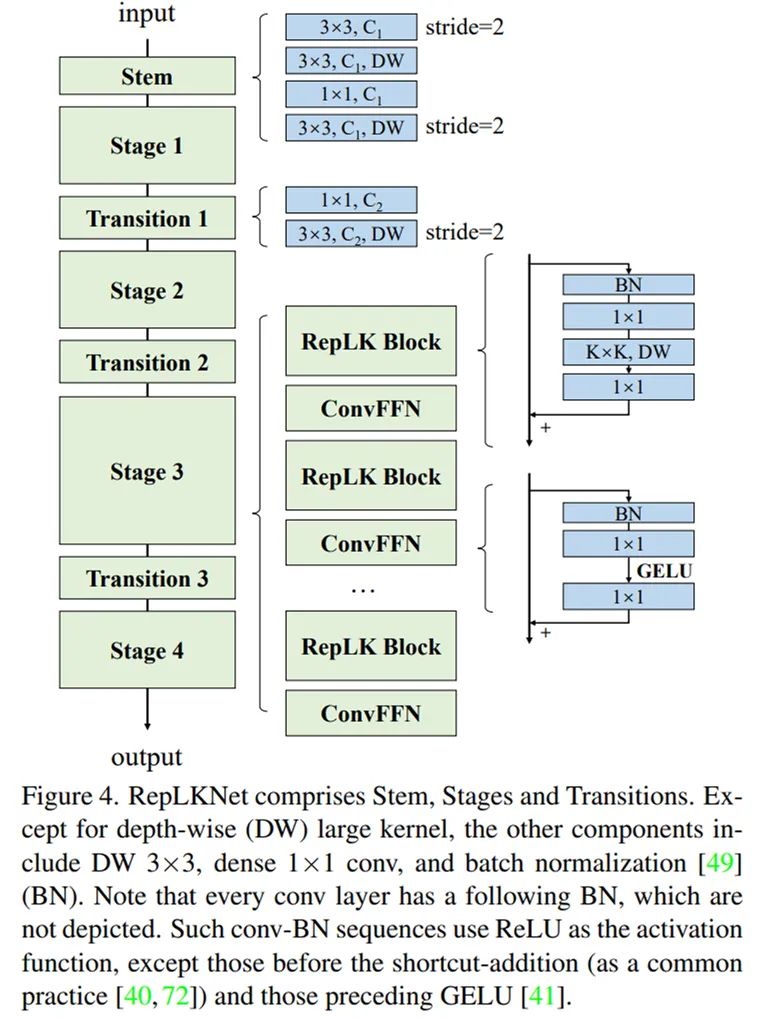 整体架构图。
越大越暴力!
在RepLKNet的4个阶段中设定不同的kernel size,在ImageNet和ADE20K的意分数据组中进行了实验,令人感兴趣的是,在ImageNet中即使从7×7增加到13×13也会上升,但13×13以后不会上升。但是在ADE 20K中,4个阶段均从13增加到4个阶段分别增加到31-29-27-13,上升0.82的mIoU,参数量只上升5.3%,FLOPs只上升3.5%。
因此,在以后的实验中,主要使用31-29-27-13的kernel size,称为RepLKNet-31B,整体扩大1.5倍,称为RepLKNet-31L。
整体架构图。
越大越暴力!
在RepLKNet的4个阶段中设定不同的kernel size,在ImageNet和ADE20K的意分数据组中进行了实验,令人感兴趣的是,在ImageNet中即使从7×7增加到13×13也会上升,但13×13以后不会上升。但是在ADE 20K中,4个阶段均从13增加到4个阶段分别增加到31-29-27-13,上升0.82的mIoU,参数量只上升5.3%,FLOPs只上升3.5%。
因此,在以后的实验中,主要使用31-29-27-13的kernel size,称为RepLKNet-31B,整体扩大1.5倍,称为RepLKNet-31L。
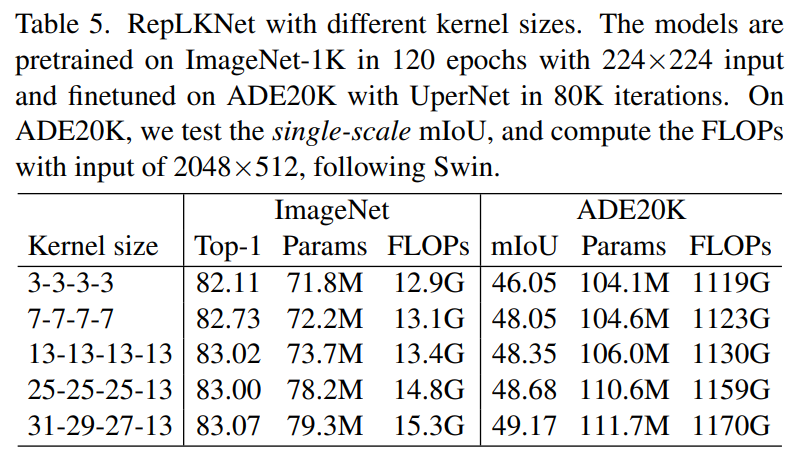 Citycapes的意思分割
在RepLKNet-31B的音量比Swin-Base稍小,仅使用ImageNet-1K pretrain的前提下,mIoU超过Swin-Large+ImageNet-22K,完成了模型级别与数据级别之间的超高。
Citycapes的意思分割
在RepLKNet-31B的音量比Swin-Base稍小,仅使用ImageNet-1K pretrain的前提下,mIoU超过Swin-Large+ImageNet-22K,完成了模型级别与数据级别之间的超高。
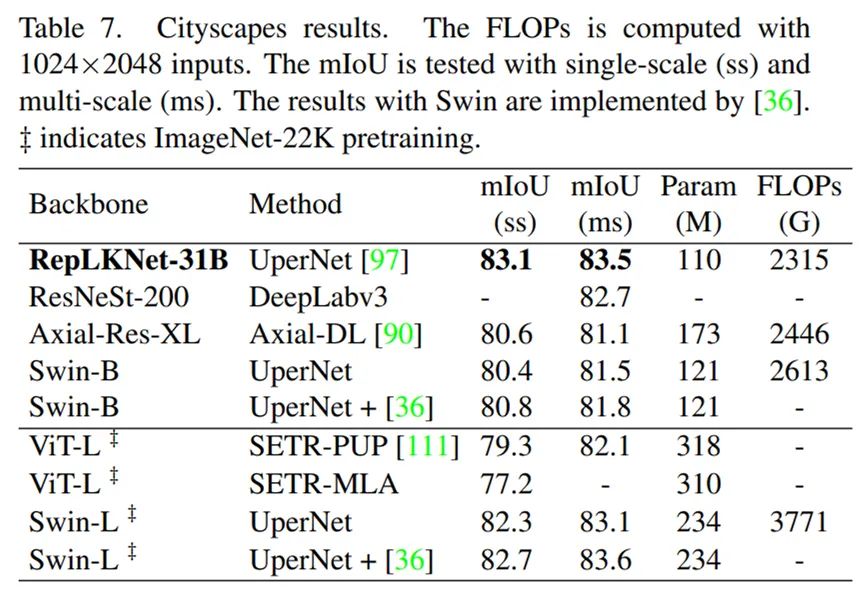 Citycapes结果。
ADE20K的意思分割
RepLKNet相当能打,特别是基本水平。与低质量差的ResNet相比,mIoU高6.1,显示了少量大kerner对大量小kerner的显著优势。(在COCO目标检测中也有同样的结论,RepLKNet-31B的mAP比相当于鳟的ResNeXt-101高4.4)RepLKNet-XL是更大的级别的模型,通过私人数据集MegData-73M进行预备训练,达到56.0的mIoU(与ViT-L相比,该模型不太大)。
Citycapes结果。
ADE20K的意思分割
RepLKNet相当能打,特别是基本水平。与低质量差的ResNet相比,mIoU高6.1,显示了少量大kerner对大量小kerner的显著优势。(在COCO目标检测中也有同样的结论,RepLKNet-31B的mAP比相当于鳟的ResNeXt-101高4.4)RepLKNet-XL是更大的级别的模型,通过私人数据集MegData-73M进行预备训练,达到56.0的mIoU(与ViT-L相比,该模型不太大)。
 ADE20K结果。
ImageNet分类、COCO目标检测结果参照“太长了不看”部分或论文。
讨论和分析
有效感受野:大kerner模型远超深层小kerner模型
RepLKNet-31、RepLKNet-13(上述各阶段为13×13的模型)、ResNet-101、ResNet-152的有效感受野(方法细节参照论文)被可视化,发现ResNet-101的有效感受野实际上很小,并且ResNet-152对101的提高也很小。RepLKNet-13的有效感受野很大,但是RepLKNet-31通过增大kernel size进一步扩大有效感受野。
ADE20K结果。
ImageNet分类、COCO目标检测结果参照“太长了不看”部分或论文。
讨论和分析
有效感受野:大kerner模型远超深层小kerner模型
RepLKNet-31、RepLKNet-13(上述各阶段为13×13的模型)、ResNet-101、ResNet-152的有效感受野(方法细节参照论文)被可视化,发现ResNet-101的有效感受野实际上很小,并且ResNet-152对101的提高也很小。RepLKNet-13的有效感受野很大,但是RepLKNet-31通过增大kernel size进一步扩大有效感受野。
 大的Kernel模型很像人
另外,人的shape bias是90%左右,参照下图左边的菱形点,关于模型的shape bias(即不是根据纹理而是根据形状预测的比例)也进行了研究。我们选择的模型包括Swin、ResNet 152、RepLKNet-31和RepLKNet-3(上述每一级都是3x3的小kernel baseline),RepLKNet-3的大小与ResNet-152的kernel size相同(3x3),shape bias也非常接近(图中的两条垂直实线几乎重叠)。
有趣的是,关于shape bias的一个工作,ViT(全局attention)的shappebias高(参照参考文献3的图),但是Swin(窗口内的局部attention)的shape bias实际上不高(下图)。这似乎表明attention的形式不重要,作用的范围重要,这也说明了RepLKNet-31的高shape bias(即像人类)。
大的Kernel模型很像人
另外,人的shape bias是90%左右,参照下图左边的菱形点,关于模型的shape bias(即不是根据纹理而是根据形状预测的比例)也进行了研究。我们选择的模型包括Swin、ResNet 152、RepLKNet-31和RepLKNet-3(上述每一级都是3x3的小kernel baseline),RepLKNet-3的大小与ResNet-152的kernel size相同(3x3),shape bias也非常接近(图中的两条垂直实线几乎重叠)。
有趣的是,关于shape bias的一个工作,ViT(全局attention)的shappebias高(参照参考文献3的图),但是Swin(窗口内的局部attention)的shape bias实际上不高(下图)。这似乎表明attention的形式不重要,作用的范围重要,这也说明了RepLKNet-31的高shape bias(即像人类)。
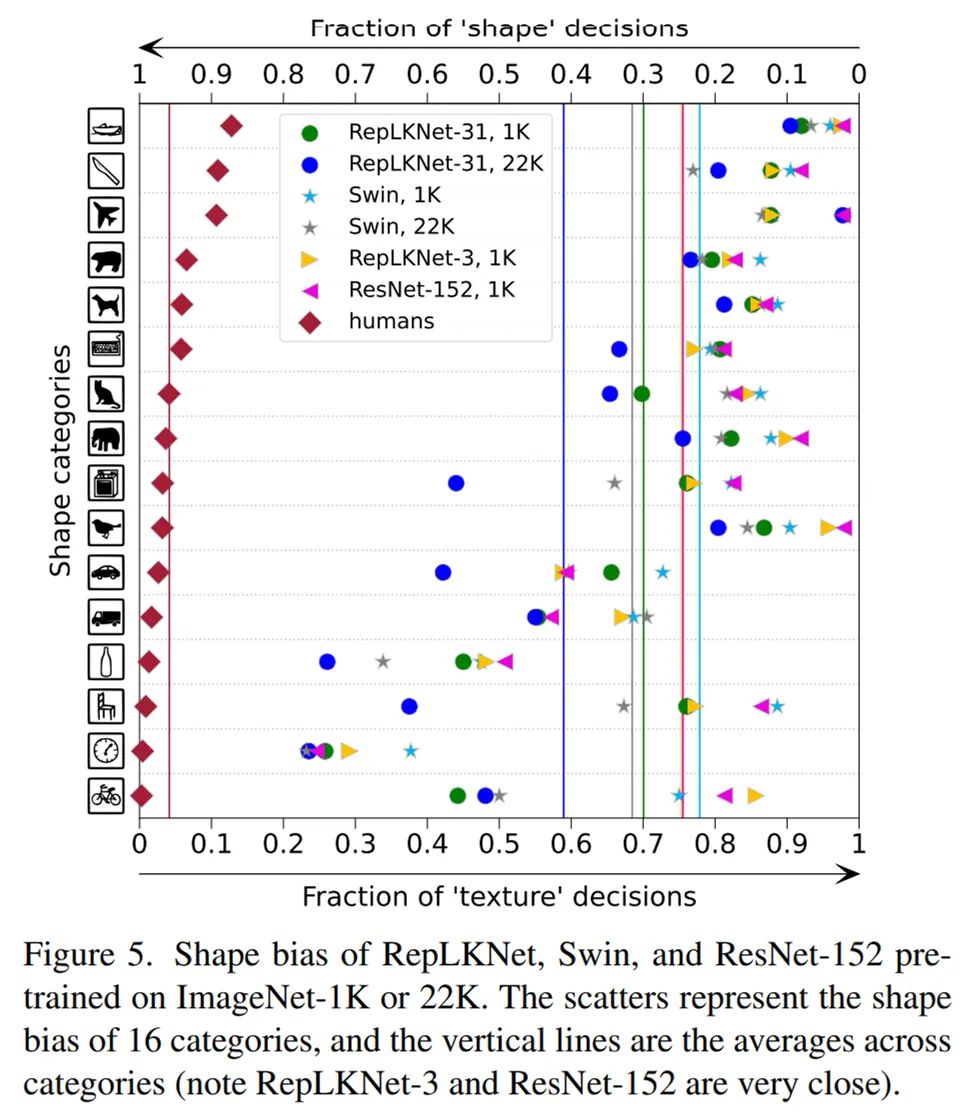 shape bias比较
对MegEngine的大kernel的强力优化
一直以来,大的kernel不受欢迎的理由之一是执行效率低。但是,开放源深度学习框架MegEngine通过分析和实验发现,大的kernel depth-wise音量仍然有较大的优化潜力,其执行时间可能比小的kernel慢得多(扩展阅读)https://zhuanlan.zhihu.com/p/479182218)。
MegEngine对大kernel depthwise音量进行多种深度优化,优化后的MegEngine性能比PyTorch快10倍,31x31尺寸的卷芯上的运行时间几乎与9x9尺寸的卷芯的运行时间差少,可以满足设备的浮点理论的峰值。MegEngine消除了对实际数据在一定意义上大的kernel音量执行效率的疑问。这些优化已经整合到MegEngine中,欢迎~
原文:https://zhuanlan.zhihu.com/p/481445076?utm_source=wechat_session&utm_medium=social&utm_oi=56560353017856&utm_campaign=shareopn
shape bias比较
对MegEngine的大kernel的强力优化
一直以来,大的kernel不受欢迎的理由之一是执行效率低。但是,开放源深度学习框架MegEngine通过分析和实验发现,大的kernel depth-wise音量仍然有较大的优化潜力,其执行时间可能比小的kernel慢得多(扩展阅读)https://zhuanlan.zhihu.com/p/479182218)。
MegEngine对大kernel depthwise音量进行多种深度优化,优化后的MegEngine性能比PyTorch快10倍,31x31尺寸的卷芯上的运行时间几乎与9x9尺寸的卷芯的运行时间差少,可以满足设备的浮点理论的峰值。MegEngine消除了对实际数据在一定意义上大的kernel音量执行效率的疑问。这些优化已经整合到MegEngine中,欢迎~
原文:https://zhuanlan.zhihu.com/p/481445076?utm_source=wechat_session&utm_medium=social&utm_oi=56560353017856&utm_campaign=shareopn
